国君海外科技:AMD MI 300表现亮眼,但暂时难以撼动英伟达的市场统治格局
国君海外科技:AMD MI 300表现亮眼,但暂时难以撼动英伟达的市场统治格局
报告导读 AMD系列新品重磅来袭,MI 300X表现亮眼,成为AI算力增量市场的有效补充,但暂未撼动英伟达在GPU市场的统治地位。
摘要
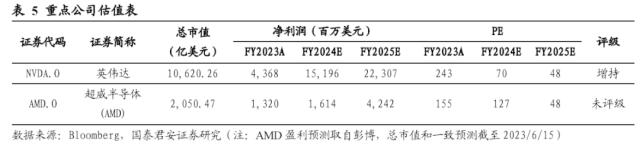
投资建议:AMD MI300系列为AI算力市场贡献增量,芯片市场“赢家通吃”英伟达仍占AI芯片主导地位,推荐标的英伟达(NVDA.O)。
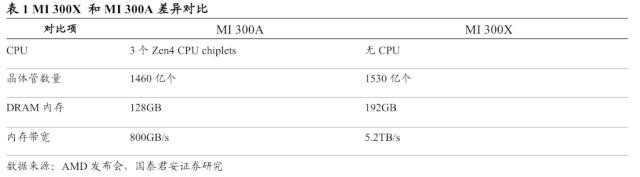
以MI 300X为代表的AMD系列新品重磅发布,整体表现亮眼。AMD举行“AMD数据中心与人工智能技术首映会”,发布了一系列新产品。其中,MI 300X针对大语言模型进行优化,产品性能大幅突破。MI 300X与MI 300A类似,由多个chiplets组成,在chiplets间内存和网络链接可实现共享。但MI300X移除了MI300A 上原有的CPU chiplets,成为了纯GPU产品。从参数上看,MI300X基于CDNA 3,拥有192GB的HBM3 DRAM内存,5.2TB/s的内存带宽,Infinity Fabric带宽896GB/s和1530亿个晶体管,采用5nm和6nm的制程并含13个chiplets。
AMD的MI 300系列产品作为全球AI算力的新供给,是AI算力增量市场有效补充,但暂时难以撼动英伟达在AI芯片市场的统治格局。第一,在硬件端,英伟达具备系统性集成竞争优势。GH200集合了Grace Hopper架构,并应用第四代Tensor Core提升计算性能、进行模型优化,以及NVLink实现高速传输,这些系统性的优化并不仅是MI 300X部分硬件参数的提升所能比拟的,而这超异构创新正形成了英伟达在硬件端的竞争壁垒,实现了芯片和系统耦合。
第二,软件端CUDA打造高兼容性的GPU通用平台,形成的壁垒短期内ROCm无法打破。CUDA具备ROCm难以企及的开发人员数量,目前CUDA 拥有超过400万开发人员,历史上CUDA总下载量达到4000万,整体而言,在发布时间、硬件支持、操作系统和开发者数量等维度上CUDA均具备优势,展现出更加繁荣的生态。
此外,量产时间、合作伙伴网络和研发人员等因素均成为了英伟达的竞争优势的有力加持。MI300 X目前仍未送样,距离实现量产也还有较长时间,仍需经过产业实践;而英伟达H100已在去年9月实现量产,GH200目前也已投入量产,上市时间指日可待;英伟达已形成了多元而庞大的客户群和完备的合作伙伴网络,整体积淀暂时优于AMD;随着英伟达研发人员数量和研发投入的高增,我们看好后续英伟达产品的迭代速度。
风险提示:AI应用发展不及预期;产品出货时间不及预期;地缘政治冲突。
目录

报告正文
1
AI算力新供给,AMD MI300新品重磅发布
在2023年6月13日AMD举行的“AMD数据中心与人工智能技术首映会”中,AMD发布了一系列新产品,包括第四代AMD EPYC(霄龙)产品组合、EPYC“Bergamo”CPU、EPYC “Genoa” CPU 、EPYC “Genoa-X” CPU、P4 DPU等。其中最受人关注的莫属AMD AI Platforms中的硬件端MI300A、MI300X和Instinct Platform的发布。
1.1.MI300A专为AI和HPC打造
MI300A成为全球首个为AI和HPC打造的APU加速卡。公司CEO苏姿丰率先公布了MI300A,称这是全球首个为AI和HPC(高性能计算)打造的APU加速卡。MI300A总共包含1460亿个晶体管,含13个chiplets,24个Zen 4 CPU核心,1个CDNA 3GPU和128GB HBM3内存,采用5nm和6nm的制程,CPU和GPU共用统一内存。与MI 250相比,MI 300A提供了8倍的性能和5倍的效率。目前,MI300A已经送样。
1.2MI300X针对LLM进行优化,性能高于MI 300A
MI 300X表现亮眼,内存带宽大幅突破。MI300X与MI 300A类似,也是由多个chiplets组成的芯片,在chiplets间内存和网络链接可实现共享。但与MI 300A不同的是,MI 300X移除了 MI300A 上原有的CPU chiplets,成为了纯GPU产品。MI300X同样基于CDNA 3,拥有192GB的HBM3 DRAM内存,5.2TB/s的内存带宽,Infinity Fabric带宽896GB/s和1530亿个晶体管,同样采用5nm和6nm的制程并含13个chiplets。MI300X计划于23Q3送样、23Q4出货。
MI300X性能显著高于MI300A。对比MI 300X 和MI 300A,MI300A是由3个Zen4 CPU chiplets和多个GPU chiplets组成的,但在MI300X中,CPU被换成了2个额外的CDNA 3 chiplets,MI300X的晶体管数量也从1460亿增加到了1530亿。为满足大语言模型对内存的需求, MI 300X的DRAM内存从MI300A的128GB增加到了192GB,内存带宽从800GB/s增加到了5.2TB/s。
MI300X是针对大语言模型进行了优化的版本。MI 300X能够在内存中处理高达800亿参数的大型语言模型的芯片,苏姿丰将其称为“生成式AI加速器”,并表示其包含的CDNA 3 GPU chiplets是专门为AI和HPC工作负载而设计。此外,她在发布会中展示了MI300X如何使用Falcon-40B大型语言模型在内存中运行一个40亿参数的神经网络,而不需要将数据在外部内存中来回移动。

MI300X部分性能可对标英伟达H100GPU。苏姿丰表示,MI300X将提供英伟达H100 Hopper GPU2.4倍的内存密度和1.6倍的内存带宽。我们认为,AMD MI300X在内存密度和内存带宽等参数上已优于英伟达可比产品,MI 300X将一定程度影响AI加速卡市场份额。

1.3 AMD Instinct Platform实现现有基础架构的直接使用
Instinct Platform实现在现有的基础架构中直接使用MI300X的AI计算能力和内存。苏姿丰在发布会中同时发布了AMD Instinct Platform,Instinct Platform将结合8个MI300X和1.5TB的HMB3内存,并采用工业级标准化设计。通过利用行业标准的OCP基础架构,Instinct Platform可直接使用MI300X的AI计算能力和内存,在降低了客户总体开发成本的基础上也加速了客户的上市时间,实现了轻松部署的效能。

2
英伟达在GPU市场统治地位短期不会改变
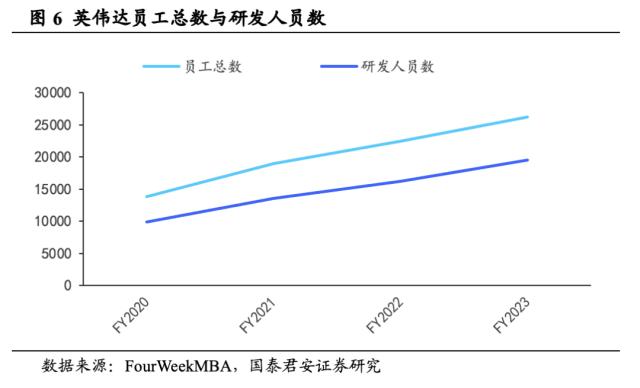
英伟达持续加大研发投入,注重创新能力培育。据FourWeekMBA统计,截至2023年1月,英伟达全球员工总数共26196人,其中研发人员19532人,研发人员占比约75%,四年间英伟达研发人员数量近乎翻倍。其中很多员工来自英特尔和AMD,由于英伟达在GPU市场的龙头地位,其对于芯片开发者而言具备较高的吸引力,头部效应吸引大量高端人才注入,因此维护了自己的研发能力优势。
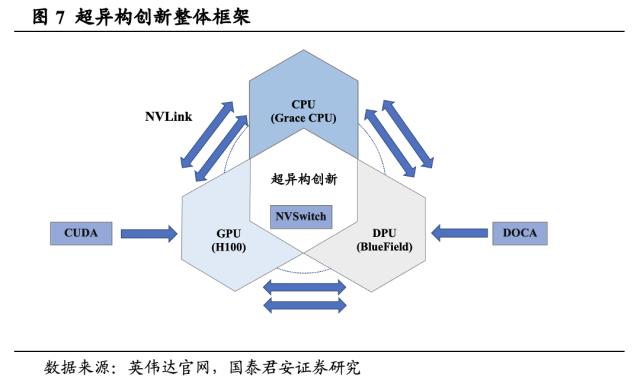
英伟达以超异构创新构建面向大规模AI计算的超级计算机。我们认为,英伟达的核心竞争优势在于,构建了AI时代面向大规模并行计算而设的全栈异构的数据中心。英伟达NVLink性能快速迭代,同时NVSwitch可连接多个NVLink,在单节点内和节点间实现以NVLink能够达到的最高速度进行多对多GPU通信,满足了在每个GPU之间、GPU和CPU间实现无缝高速通信的需求,同时基于DOCA加速数据中心工作负载的潜力,实现DPU的效能提升,GPU +Bluefield DPU+Grace CPU的结合开创性地实现了芯片间的高速互联。同时CUDA充当通用平台,引入英伟达软件服务和全生态系统。我们认为,芯片和系统耦合的实现使得英伟达真正实现了超异构创新。
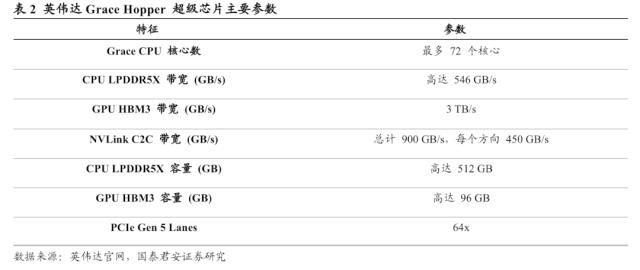
英伟达自研Grace Hopper超级芯片,为AI数据中心而生。Grace Hopper是适用于大规模AI和HPC应用的突破性加速CPU。通过NVLink-C2C 技术将Grace和Hopper架构相结合,为加速AI和HPC应用提供 CPU+GPU 相结合的一致内存模型。它采用新型900 GB/s一致性接口,比PCIe 5.0快7倍,并可运行所有的英伟达软件栈和平台,包括 NVIDIA HPC SDK、NVIDIA AI和NVIDIA Omniverse。
英伟达CUDA构筑软件业务底层框架基石,打造高兼容性的GPU通用平台。借助英伟达 CUDA 工具包,开发者可以在GPU加速的嵌入式系统、桌面工作站、企业数据中心、基于云的平台和HPC超级计算机上开发、优化和部署应用程序。CUDA最初用于辅助GeForce提升游戏开发效率,但随着CUDA的高兼容性优势彰显,英伟达将GPU的应用领域拓展至计算科学和深度学习领域。CUDA可以充当英伟达各GPU系列的通用平台,因此开发者可以跨GPU配置部署并扩展应用。目前,通过 CUDA 开发的数千个应用目前已部署到嵌入式系统、工作站、数据中心和云中的GPU。
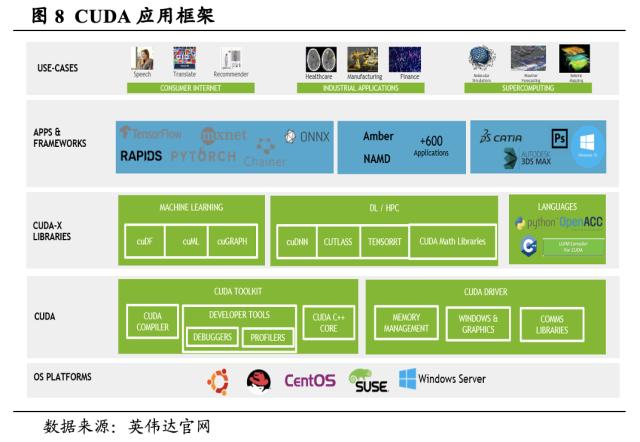
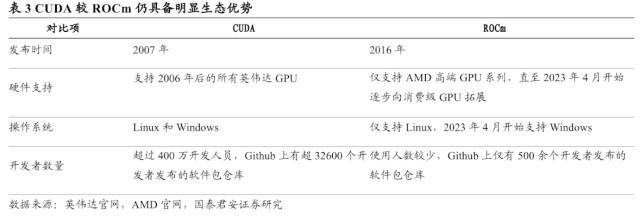
CUDA形成的壁垒短期内ROCm无法打破,成为英伟达与AMD市场份额差距的重要影响因素。在COMPUTEX 2023中,英伟达表示,目前CUDA 拥有超过400万开发人员,历史上CUDA 的总下载量也达到惊人的4000万。而ROCm作为AMD为对标英伟达而打造的开放式软件平台,2016年4月首次发布,相比2007年发布的CUDA目前使用的人数依旧较少。ROCm操作系统直至2023年4月才支持Windows,改变了仅支持Linux的尴尬局面,同时长期仅支持Radeon Pro系列GPU,近期才开始陆续拓展。此外,ROCm缺少类似于CUDA的社区支持和成熟的生态体系。我们认为,目前CUDA已形成极高的准入壁垒,也成为了英伟达持续扩展人工智能领域市场的品牌影响力来源,带动了英伟达GPU的高市场份额,短期内ROCm的软件支持难以匹敌CUDA。

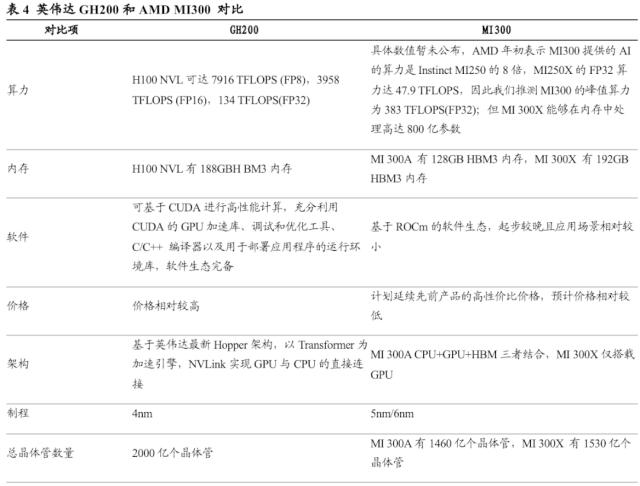
MI 300较英伟达GH 200部分硬件参数差距有望对标,但整体仍存在一定差距。GH200超级芯片是英伟达系统性竞争优势的集大成者,将72核的Grace CPU、H100 GPU、96GB的HBM3和512 GB的LPDDR5X 集成在同一个封装中,它集合了最先进的Grace Hopper架构,并应用第四代Tensor Core提升计算性能、进行模型优化,NVLink实现了高速的传输,这都将进一步形成英伟达的竞争壁垒。通过将英伟达GH 200和MI 300进行对比,我们认为,MI 300还有许多参数有待后续公布,但从算力、内存等指标上有望和英伟达实现对标,但在架构、制程和晶体管数量上仍与英伟达GH 200存在一定差距。

芯片市场具有一定的“赢家通吃”性。1)以全球x86 CPU服务器处理器市场为例,据Mercury Research,英特尔占超80%的市场份额;2)以独立显卡市场为例,据JPR测算,英伟达长期占全球独立显卡的市场份额近80%;3)以基带芯片市场为例,据TechInsights,高通在2022年以61%的收入份额领先基带芯片市场。而目前,英伟达就基于其繁荣的生态,构筑了AMD暂时难以逾越的生态壁垒。
综上所述,我们认为英伟达短期内仍占AI芯片主导地位,主要基于如下原因:
1)英伟达具备系统性集成竞争优势,GH200集合了Grace Hopper架构,并应用第四代Tensor Core提升计算性能、进行模型优化,以及NVLink实现高速传输,这些系统性的优化并不仅是部分硬件参数的提升所能比拟的,而这超异构创新正是英伟达在硬件端的竞争壁垒,实现了芯片和系统耦合;
2)CUDA具备ROCm难以企及的开发人员数量,而英伟达基于CUDA而形成的软件生态的繁荣程度高于AMD的ROCm;
3)MI300 X目前仍未送样,距离实现量产可能也还有较长时间,仍需经过产业实践;而英伟达H100已在去年9月实现量产,GH200目前也已投入量产,上市时间指日可待;
4)英伟达已形成了多元而庞大的客户群和完备的合作伙伴网络,在其合作伙伴网络列表中,截止2023年6月14日,共公示了976家公司,英伟达的客户群和合作伙伴积淀暂时优于AMD;
5)研发人员的数量反映了公司长期的研发能力,随着英伟达研发人员数量和研发投入的高增,我们看好后续英伟达产品的迭代速度。
整体而言,AMD的MI 300系列产品作为全球AI算力的新供给,是AI算力增量市场有效补充,但暂时难以撼动英伟达的市场统治格局,推荐标的英伟达(NVDA.O)。
3
风险提示
AI应用发展不及预期;产品出货时间不及预期;地缘政治冲突。
-
十大行业互联网金融-想借钱?先交“评估”费
2024-05-09
-
Xi人最近像买彩票一样抢疫苗号3000 家长只能拿到24个左右的号
2024-05-09
-
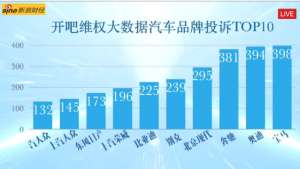
走吧维权汽车品牌投诉名单公布-东风日产上汽大众榜上有名
2024-05-09

-
绿瘦“魔粉”轻松瘦?客户说花了8万减肥 住进了医院
2024-05-09
-
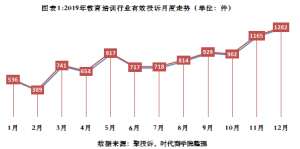
消费者权益保护教育培训白皮书-预付式消费陷阱大
2024-05-09

-
视频-华晨宝马因漏油召回31万辆车 品控成焦点
2024-05-09